KI-gestützte Vorhersagen

Seit dem Siegeszug von ChatGPT ist Künstliche Intelligenz (KI/AI) ein Megathema. Grund genug, sich einmal deren Grundprinzipien anhand eines überschaubaren, praktischen Beispieles klar zu machen: Der Vorhersage (Prediction) von Aktienkursen.
Genauer formuliert: Ein neuronales Netz soll so trainiert werden, dass es anhand von Zeitreihen mit Kursrohdaten als Eingabe einen Wahrscheinlichkeitwert für einen zukünftigen Aktienkurs als Ausgabe ermittelt.
Den dazu verwendeten Quellcode finden Sie hier: rate-ai-predict.
Programmiersprache und Framework
Für explorative und visuelle Programmierung mit neuronalen Netzen ist Python zusammen mit dem KI Framework Keras prädestiniert. Keras ist ein hochabstraktes Framework zur Spezifikation von Modellen für neuronale Netze, deren Training und spätere Verwendung. Es ist im Kontext von Tensorflow entstanden und verwendet dieses im Normalform als Backend-Engine für seine mathematische Berechnungen. Alternativ stehen auch Engine-Schnittstellen zu cntk (Microsoft) sowie Theano (leider abgekündigt) zur Verfügung.
Tensorflow wiederum implementiert seine Operationen - falls eine passende Nvidia Graphikkarte verfügbar ist - mittels CUDA, d.h. die mathematischen Operationen (insbesondere Matrixberechnungen) werden massiv parallel auf die Kerne der GPU verteilt.
Für Besitzer einer AMD-Graphikkarte mit ROCm steht ebenfalls eine Tensorflow-Implementierung bereit.
Leider wird der offene Standard OpenCL nur rudimentär unterstützt. PlaidML kann zwar alternativ zu Tensorflow als Engine für Keras verwendet werden; aktuell leider nur mit einer veralteten Version von Keras.
Falls Sie weder eine Graphikkarte mit CUDA oder ROCm Unterstützung besitzen, dann müssen Sie an dieser Stelle die Lektüre dieses Artikel nicht beenden: Sie verwenden gerade mit großer Wahrscheinlichkeit eine CPU die ebenfalls recht effizient parallele Operationen durchführen kann! Dazu gibt es bei modernen x86 CPUs die Befehlssatzerweiterungen AVX2 und FMA, die für unsere Beispielanwendung absolut ausreichen. Die CPU wird von Tensorflow entsprechend als Fallback genutzt.
Tempus fugit
APIs für hochfrequente Aktienkurse sind kostenpflichtig. Zum Glück stellt yahoo eine kostenfreie, eingeschränkte API zur Verfügung, die mittels der Python-Libraries yfinance (Aktienticker) und pandas (Zeitreihen) verwendet werden kann.
>>> from yfinance import Ticker
>>> candle_df = Ticker('GOOG')
.history(start='2023-01-01', end='2023-07-01')
[['Open','Close','High','Low']]
>>> type(candle_df)
<class 'pandas.core.frame.DataFrame'>
>>> candle_df.head(5)
Open Close High Low
Date
2023-01-03 00:00:00-05:00 89.830002 89.699997 91.550003 89.019997
2023-01-04 00:00:00-05:00 91.010002 88.709999 91.239998 87.800003
2023-01-05 00:00:00-05:00 88.070000 86.769997 88.209999 86.559998
2023-01-06 00:00:00-05:00 87.360001 88.160004 88.470001 85.570000
2023-01-09 00:00:00-05:00 89.195000 88.800003 90.830002 88.580002Das neuronale Netz soll mit abgeleiteten Zeitreihen trainiert werden; exemplarisch wird dazu der rollierende Mittelwert (zur "Glättung" des Kursverlaufs) sowie die Bollinger Bandweite verwendet. Wenn Sie mögen können Sie gerne auch mit anderen Indikatoren (z.B. RSI) experimentieren. Das Modellieren von neuronalen Netzen ist eher eine explorative Kunst denn eine Wissenschaft.
def _calc_bolling(candle_df: DataFrame, window: int):
candle_df['TP'] = \
(candle_df['Close']+candle_df['Low']+candle_df['High']) / 3
candle_df['STD'] = candle_df['TP'].rolling(window).std()
# Rollierender Mittelwert
candle_df['MATP'] = candle_df['TP'].rolling(window).mean()
# Bollinger Bänder
candle_df['BOLU'] = \
candle_df['MATP'] + (2.0 * candle_df['STD'])
candle_df['BOLD'] = \
candle_df['MATP'] - (2.0 * candle_df['STD'])
# Bandweite
candle_df['BOBW'] = \
(candle_df['BOLU'] - candle_df['BOLD']) / candle_df['MATP']Mittelwert und Bandweite mit Matplotlib visualisiert:
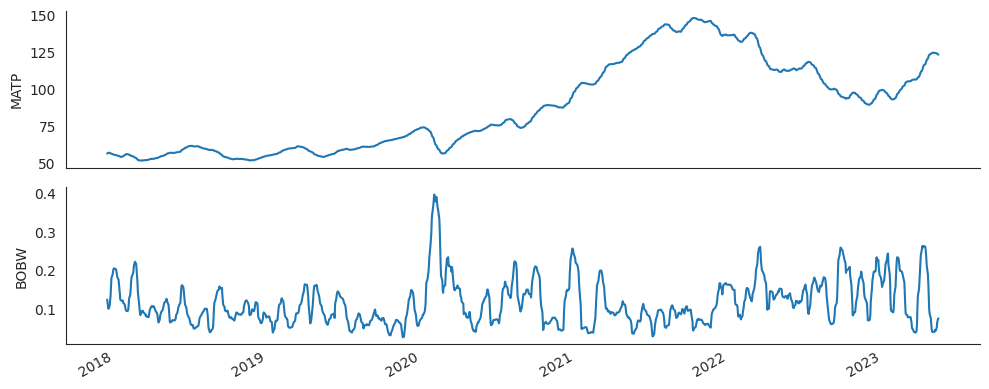
Die Ausbrüche Anfang 2020 sind bemerkenswert.
Neuronale Netze - (sehr) kurz zusammengefasst
Wenn Sie an ein neuronales Netz denken (oder auf wikipedia schauen), dann stellen Sie sich dies vermutlich so vor:

Ergo: An den "grünen" Eingangsneuronen liegen jeweils skalare Fließkommazahlen an und die Ausgangsneuronen (hier ein einzelnes "gelbes" Neuron) liefern skalare Ergebnisse zurück. Dazwischen liegen innere Neuronen-Schichten (hier eine Schicht mit "blauen" Neuronen).
Ein Blick auf ein einzelnes Neuron zeigt dessen recht einfache mathematische Struktur:

Ein Neuron erhält also die Ausgaben der Vorgängerschicht als gewichtete Eingaben, akkumuliert diese (Übertragungsfunktion) und berechnet via Aktivierungsfunktion (oft eine einfache Gleichrichter/ReLU-Funktion
max(0, x)) seine Ausgabe, also ob und wie stark es aktiviert ist.
Bei dem Trainieren eines neuronalen Netzes geht es schlicht darum, die Gewichtungsmatrizen w_ij der Neuronen zu bestimmen.
Dazu (überwachtes Lernen meist mit Backpropagation) verwendet man bekannte
Kombinationen von Eingangs-/Ausgabewerten - die Trainingsdaten (Faustregel: Minimale Datenlänge von etwa 1000).
Für das erfolgreiche Trainieren eines neuronalen Netzes ist hier die Verlustfunktion (Loss Function) zentral.
In unserem Zeitreihenkontext bieten sich hier Huber, Mean Absolute Error und Mean Squared Error an.
Keine Sorge, Keras ist wie beschrieben ein high-level Framework, d.h. man muss diese Funktion nicht selber implementieren sondern "nur"
sinnvoll auswählen.
Das Model
Hiermit ist nicht das Lied von Kraftwerk gemeint, sondern das von Keras verwendete Modell für das zu trainierende neuronale Netz.
Bei der Lektüre der obigen (sehr kurzen und knappen) Zusammenfassung werden Sie vermutlich gestutzt haben: Wie soll für Zeitreihendaten, also "Werten mit Vergangenheit" in einem neuronalen Netz die Eingabe erfolgen? Man kann doch anscheinend nur jeweils aktuelle Skalardaten an die Neuronen anlegen!
Das haben sich findige Informatiker in den 90er Jahren auch gefragt und mit Long short-term memory(LSTM) das Konzept neuronaler Netze passend erweitert. Falls Sie sich jetzt unter LSTM komplexe und ggf. teure Caching/Speicher Systeme vorstellen, dann kann ich Sie beruhigen: Im Prinzip geht es bei LSTM lediglich darum, die Ausgabe eines Neurons als zusätzliche Eingabe rückzukoppeln und damit zeitlich "alte" Eingaben beim Trainieren passend zu gewichten. Und: Auch LSTM bekommen Sie mit Keras programmatisch in Form einer Python-Klasse geschenkt!
Die multidimensionale Eingabe (Tensor) wird dazu in Keras mittels der Python Library NumPy formuliert.
Für unser Projekt findet das folgende Modell Verwendung:
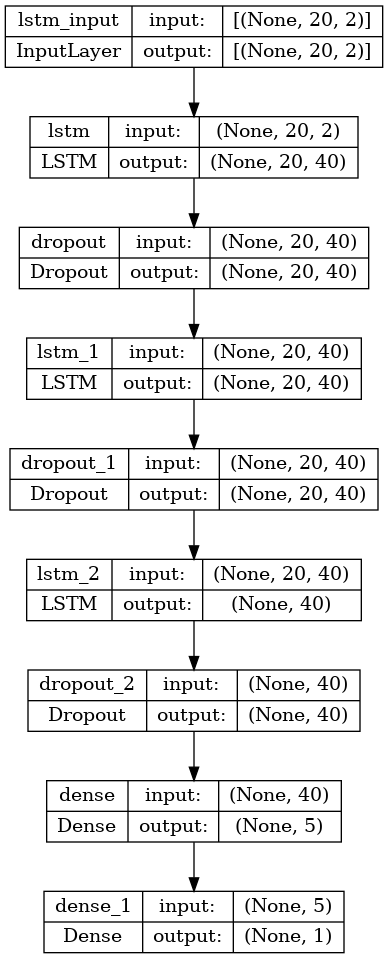
-
Eingabe-Tensor mit der Dimension n * 20 * 2 (n: Länge der Zeitreihen, 20: Anzahl Eingabeneuronen, 2: Features MATP und BOBW )
-
Zwei innere Schichten (hidden layer) mit 20 Neuronen, jeweils mit Dropouts zur Verringerung von Overfitting
-
Eine skalare Ausgabe
In Python/Keras lässt sich diese folgendermaßen kodieren:
def _gen_lstm_model(input_shape: tuple, in_units: int, out_units: int,
preout_units: int,
dropout: float = None,
hidden_layer=1) -> Model:
model = Sequential()
model.add(LSTM(in_units, return_sequences=hidden_layer > 0,
input_shape=input_shape))
if dropout is not None:
model.add(Dropout(dropout))
for i in range(1, hidden_layer + 1):
model.add(
LSTM(units=in_units, return_sequences=i < hidden_layer)
)
if dropout is not None:
model.add(Dropout(dropout))
if preout_units is not None:
model.add(Dense(preout_units))
model.add(Dense(out_units))
return modelSkalierung
Neuronale Netze funktionieren am besten, wenn die Eingabewerte auf einen Wertebereich von 0..1 skaliert sind.
Die als Tensoren (in Programmierer Sprache: mehrdimensionale Felder) verwalteten Trainingsdaten sind entsprechend für unsere Features MATP
(Mittelwerte) und BOBW (Bandweite) zu skalieren.
Auch Skalierer müssen nicht selber programmiert werden:
Die Scikit-learn Library stellt dazu die Klasse sklearn.preprocessing.MinMaxScaler
zur Verfügung.
Skalierte Trainingdaten lassen sich mit etwas Python-Code implementieren:
def _init_scaler(self):
data_df = self._rate_df[self._features].dropna()
index_rate = data_df.columns.get_loc(self._rate_col)
self._data_scaler = MinMaxScaler()
self._pred_scaler = MinMaxScaler()
self._pred_scaler.fit(DataFrame(data_df[self._rate_col]))
data_np_unscaled = data_df.to_numpy()
data_np_scaled = self._data_scaler.fit_transform(data_np_unscaled)
train_data_len = \
math.ceil(data_np_scaled.shape[0] * self._train_data_ratio)
train_data_scaled = data_np_scaled[0:train_data_len, :]
self._train_scaled_tuple = \
self._partition_dataset(sequence_len=self._neurons,
gap_len=self._predict_gap_len,
index_rate=index_rate,
data_np=train_data_scaled)Die eigentliche Magie führt dabei die Methode _partition_dataset() durch:
Sie partitioniert die Zeitreihen-Daten in für das neuronale Netz verarbeitbare
Datenhäppchen: Jeweils ein Tupel für die Eingabe (x: für 20 Neuronen) und einem Wert y für die zu trainierende
Ausgabe.
def _partition_dataset(sequence_len: int, gap_len: int, index_rate: int, data_np: np.ndarray) \
-> (np.ndarray, np.ndarray):
x, y = [], []
data_len = data_np.shape[0] - gap_len
for i in range(sequence_len, data_len):
x.append(data_np[i - sequence_len:i])
y.append(data_np[i + gap_len - 1, index_rate])
x = np.array(x)
y = np.array(y)
return x, yDas Training
Wir haben ein Modell für das neuronale Netz. Wir haben aufbereitete und skalierte Trainingsdaten. Jetzt kann trainiert werden! Die Trainingsdaten werden in Batches organisiert/parallelisiert und wiederholt in Epochen abgearbeitet - solange bis eine maximale Anzahl von Epochen erreicht ist oder bis das neuronale Netz sich nicht mehr verbessert. Abschliessend wird das trainierte neuronale Netz gespeichert.
def train(self):
x_train, y_train = self._train_scaled_tuple
model_name = f'{self._MODEL_NAME_PREFIX}_{self._symbol}'
callbacks = [
ReduceLROnPlateau(
monitor="val_loss", factor=0.5,
patience=20, min_lr=0.0001
)
]
if self._stop_early:
callbacks.append(EarlyStopping(monitor='loss', patience=10, verbose=1))
self._history = \
self._model.fit(x_train, y_train,
batch_size=self._batch_size,
epochs=self._epochs,
callbacks=callbacks,
validation_split=self._validation_split)
model_path = Path(AI_PATH, f'{model_name}.keras')
if not model_path.parent.exists():
model_path.parent.mkdir()
self._model.save(filepath=model_path,
save_format='keras', overwrite=True)Epoch 1/100 27/27 [==============================] - 3s 27ms/step - loss: 0.0833 - val_loss: 0.1104 - lr: 0.0010 Epoch 2/100 27/27 [==============================] - 0s 8ms/step - loss: 0.0346 - val_loss: 0.0375 - lr: 0.0010 Epoch 3/100 27/27 [==============================] - 0s 9ms/step - loss: 0.0257 - val_loss: 0.0786 - lr: 0.0010 Epoch 4/100 27/27 [==============================] - 0s 9ms/step - loss: 0.0268 - val_loss: 0.0430 - lr: 0.0010 ... Epoch 59/100 27/27 [==============================] - 0s 8ms/step - loss: 0.0145 - val_loss: 0.0379 - lr: 0.0010 Epoch 59: early stopping
Vertrauen ist gut…
…Kontrolle ist besser!
Dazu kann das Trainingsergebnis mit Matplotlib visualisiert werden:
def plot_model_loss(self):
sns.lineplot(data=self._history.history['loss'])
plt.title(f'Model loss {self._symbol}')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.grid()
plt.show()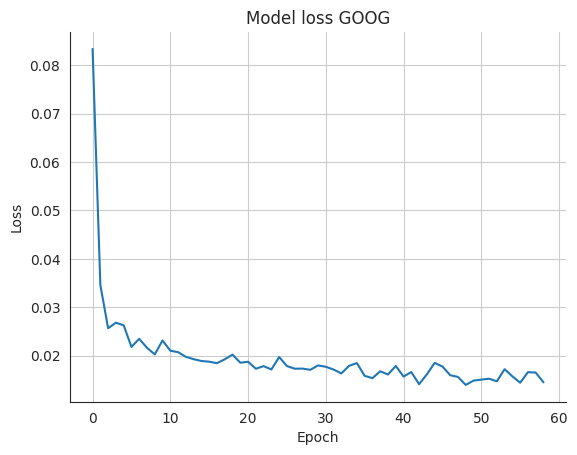
-
Das Netz verbessert sich in den ersten Epochen sehr schnell (Verlust/Loss nimmt stark ab)
-
Ab ca. Epoche 40 verbessert es sich mehr signifikant
-
In Epoche 59 wird das Training beendet
Wie gut funktioniert das Netz?
Um dies zu prüfen wird das Netz mit (skalierten) Testdaten gestartet und die dabei generierten Vorhersagedaten werden
mit den Testdaten abgeglichen; die Vorhersagedaten müssen dazu mit den MinMaxScaler-Instanzen
wieder deskaliert (inverse_transform()) werden:
def test_model(self):
x_test_scaled, _ = self._test_scaled_tuple
_, y_test_unscaled = self._test_unscaled_tuple
y_test_unscaled = y_test_unscaled.reshape(-1, 1).reshape(-1, 1)
y_pred_scaled = self._model.predict(x_test_scaled)
self._y_pred_unscaled = \
self._pred_scaler.inverse_transform(y_pred_scaled)
mae = mean_absolute_error(y_test_unscaled, self._y_pred_unscaled)
print(f'Median Absolute Error (MAE): {mae}')
mape = \
np.mean( \
(np.abs( \
np.subtract(y_test_unscaled,
self._y_pred_unscaled) / y_test_unscaled))) * 100
print(f'Mean Absolute Percentage Error (MAPE): {mape} %')
mdape = \
np.median( \
(np.abs( \
np.subtract(y_test_unscaled,
self._y_pred_unscaled) / y_test_unscaled))) * 100
print(f'Median Absolute Percentage Error (MDAPE): {mdape} %')Median Absolute Error (MAE): 3.81 Mean Absolute Percentage Error (MAPE): 3.64 % Median Absolute Percentage Error (MDAPE): 3.4 %
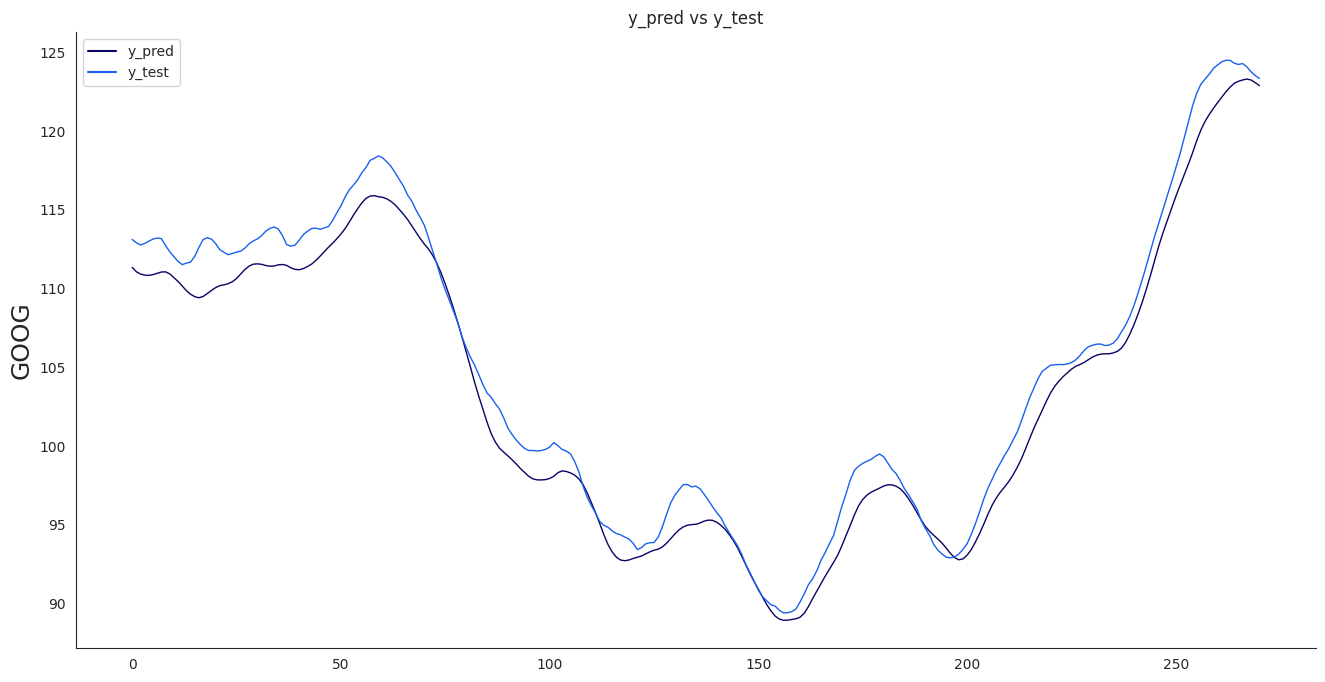
Diese Fehlerquoten sind passabel. Schauen wir uns das einmal visuell (Matplotlib) an:
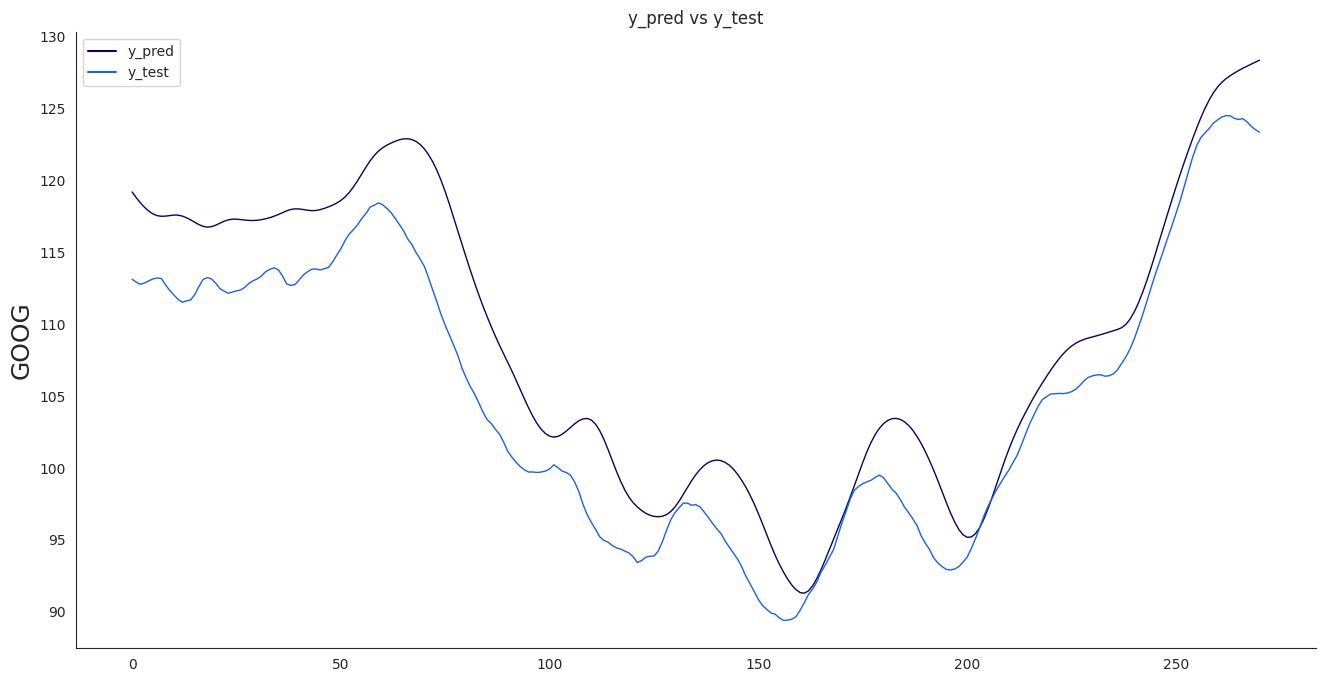
Die Vorhersage- (y_pred) und die realen Daten (y_test) liegen nah beieinander. Das Netz übersteuert etwas.
Erweitert man die Features (MATP, BOBW) um den RSI, dann verbessert sich das Resultat (zumindest für die Testdaten):
Man kann jetzt mit anderen Indikatoren weiter experimentieren. Vielleicht finden Sie dabei den Stein der Weisen und können Ihren Traum von der eigenen Inselkette oder privaten Raumfahrtagentur verwirklichen. Ich drücke Ihnen - trotz des folgenden Caveats - die Daumen!
Caveat!
Nach der Lektüre dieses Artikels werden Sie vermutlich reicher an Erkenntnis sein. Falls Sie sich jetzt mit dem Gedanken tragen sollten, unser kleines Demonstrationprojekt für Ihre eigene Tradingstrategie zu nutzen, dann werden mit großer Wahrscheinlichkeit nicht Sie sondern andere Leute (monetär) reicher.
Zu dem Thema Python bieten wir sowohl Beratung, Entwicklungsunterstützung als auch eine passende Schulung an:
Auch für Ihren individuellen Bedarf können wir Workshops und Schulungen anbieten. Sprechen Sie uns gerne an.